
حدود ۴ سال پیش با پروژهٔ آواهای مشترک موزیلا آشنا شدم. آن زمان مجموعه دادهٔ (Dataset) فارسی پروژه تنها حدود ۲ گیگابایت بود. الآن زبان فارسی تقریبا ۱۰ گیگابایت مجموعه داده دارد. در این مطلب راجع به پروژه و اهمیت آن برای پروژههای یادگیری ماشینی و هوش مصنوعی توضیح میدهم. البته موضوع دورهمی نهم کرمهای کامپیوتر هم در همین مورد بود.
یادگیری ماشینی و تشخیص گفتار چیست؟
به زبان ساده و به صورت نادقیق، یادگیری ماشینی حوزهای از دانش کامپیوتر است که در آن سعی میکنیم با ارائه داده به کامپیوتر یک مدل بسازیم که بتواند خودش زمانی که دادههای مشابهی دید تصمیم بگیرد. یک مثال از این تصمیمگیری، تشخیص این است که کاربر واژهای خاص را به زبان آورده یا خیر. البته موضوع دورهمی چهاردهم (۲۹ دی ماه) هم در همین مورد است.
به عنوان مثال، میتوانیم به کامپیوتر ۱٬۰۰۰ نمونه پروندهٔ صوتی واژهٔ «سلام» و ۹٬۰۰۰ پرونده صوتی برای دیگر واژهها بدهیم. و به آن یاد بدهیم تشخیص بدهد واژهای که یک انسان به زبان میآورد، واژهٔ «سلام» میباشد یا خیر. این یک نمونه ساده از پروژهای است که میتوان به یک مجموعه داده صوتی و یادگیری ماشین انجام داد. کاربرد همچین پروژهای در بیدار کردن و گوش به فرمان کردن دستیارهای صوتی است (wake word) مثل (Hey Siri) برای دستیار صوتی iOS.
البته مسائل یادگیری ماشینی به این کاربرد کوچک و ساده محدود نمیشوند. یک کاربرد دیگر یادگیری ماشینی در «تشخیص گفتار» است. تشخیص گفتار به زبان ساده به این معنی است که ماشین از روی دادهٔ صوتی تشخیص بدهد انسان چه جملهای را به زبان آورده است. تشخیص گفتار نیز در دستیارهای صوتی کاربرد دارد تا کاربر با دادن فرمانهای صوتی ماشین را به کار گیرد. و علاوه بر این، به صورت کلی ارتباط گفتاری و صوتی انسان با کامپیوتر را میسر میکند.
اما برای یادگیری ماشینی به یک مجموعه داده یا dataset نیازمندیم (البته به صورت نادقیق). در مثال بالا (کلمه بیداری) برای تشخیص یک کلمه به ۱۰٬۰۰۰ پرونده صوتی نیاز داشتیم. و البته هرچقدر تعداد دادههای نمونه بیشتر و متنوعتر باشد، ماشین بهتر یاد میگیرد.
اهمیت پروژهٔ آواهای مشترک موزیلا
همانطور که در قسمت قبل توضیح دادم، برای کاربردهای یادگیری ماشینی نیازمند یک مجموعه داده هستیم که هرچقدر بزرگتر باشد بهتر است. متأسفانه این مجموعهها در اختیار افراد کمی هستند. البته دادههای باز نیز داریم؛ اما بسیاری از اوقات حجم آنها کم و برای کاربردهای آزمایشی مناسب هستند.
آواهای مشترک تلاش میکند برای زبانهای مختلف دادههای صوتی تایید شده جمعآوری کند و آنها را در اختیار همه و در مالکیت عمومی قرار دهد. به این ترتیب هر کس قادر است تا پروژههای یادگیری ماشینی مبتنی بر گفتار را برای زبانهای مختلف پیادهسازی و اجرا کند. هرکس میتواند در آوای مشترک با گوش دادن، گفتن، نوشتن و بازبینی کردن مشارکت کند. در قسمت بعدی کمی راجع به این موضوع توضیح داده میشود.
نحوه مشارکت در آواهای مشترک
نحوهٔ مشارکت در آواهای مشترک ساده است و حتی به یک حساب در این وبسایت نیز نیازی ندارید. هرچند که داشتن حساب میتواند برای مشارکتهای طولانی مدت بهتر باشد. زمانی که وارد وبسایت آواهای مشترک به آدرس commonvoice.mozilla.org میشوید، بالای صفحه باید زبان را انتخاب کنید:
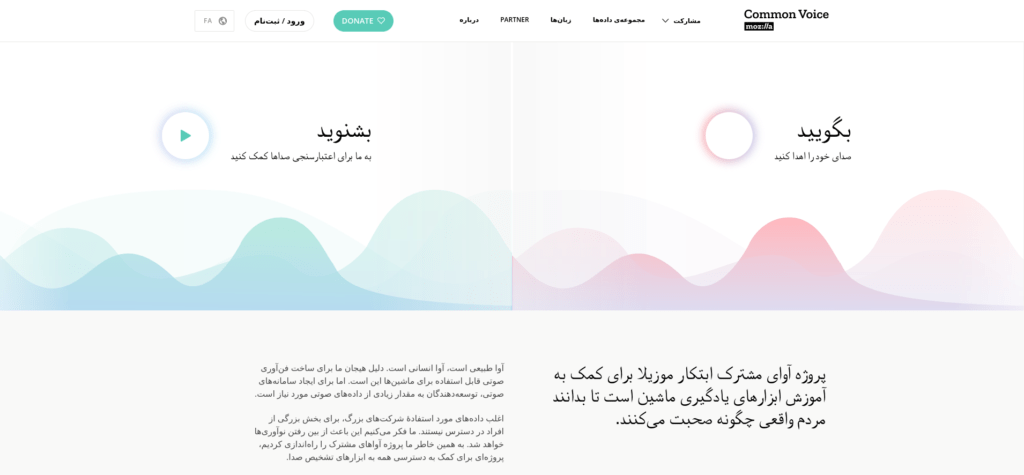
بعد از تغییر زبان به فارسی، زبان مشارکت و زبان رابط کاربری وبسایت به فارسی تغییر میکند.
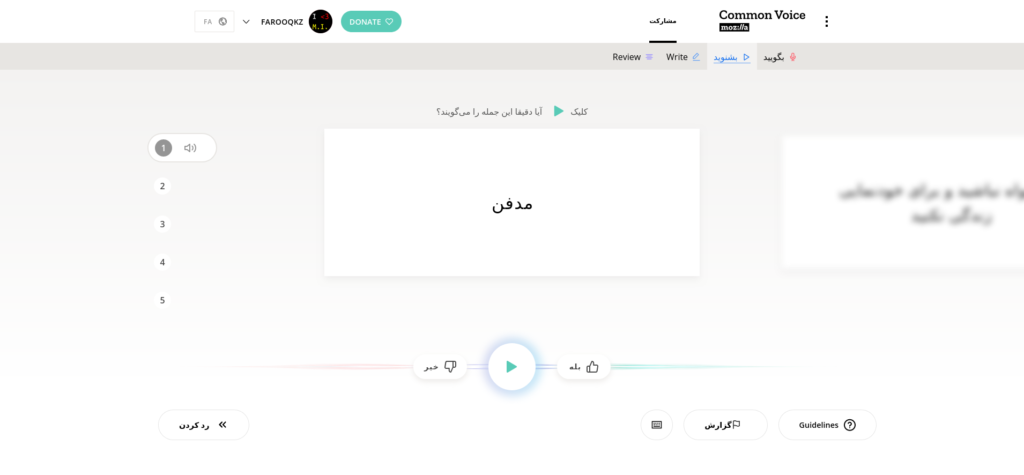
حال با کلیک روی دکمهی «بشنوید» میتوانید قطعههای صوتیای که دیگران ضبط کردهاند را گوش دهید. در صورتی که جملهی تلفظ شده در قطعه صوتی با جملهی روی صفحه مطابقت دارد، گزینه بله و در غیر این صورت گزینه خیر را بزنید.
همچنین در قسمت «بگویید» نیز در صورتی که میکروفن داشتید، میتوانید جملهی روی صفحه را تلفظ کنید.
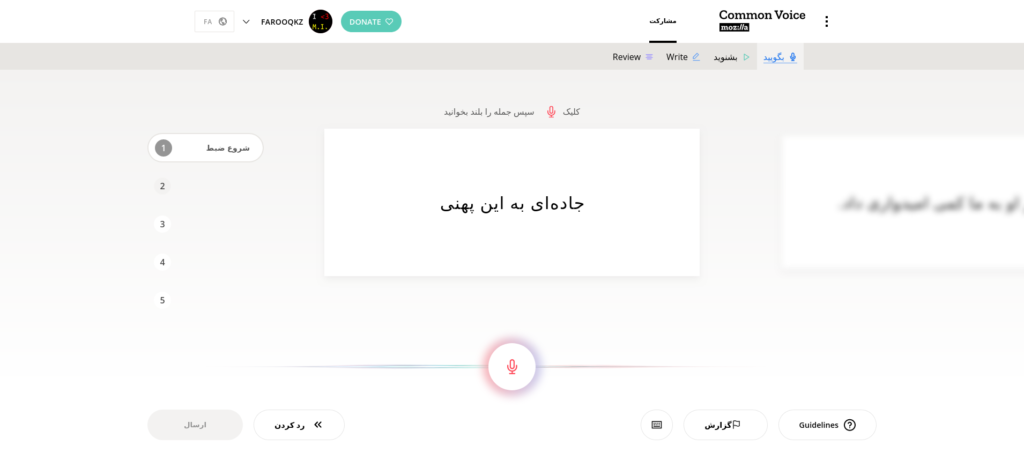
با زدن کلید میکروفن، شروع به ضبط کردن میکند و با دوباره زدن آن، ضبط خاتمه پیدا کرده و به سراغ عبارت بعدی میرود. البته میتوانید جملات رو رد یا ضبط مجدد هم بکنید.
همچنین با رفتن به بخش «بنویسید» (در تصویر Write) و «بررسی کنید» (در تصویر Review) میتوانید جمله بنویسید یا جملههای دیگران را بررسی کنید تا نهایتا این جملهها توسط کاربران تلفظ شده و به دیتاست اضافه شود.
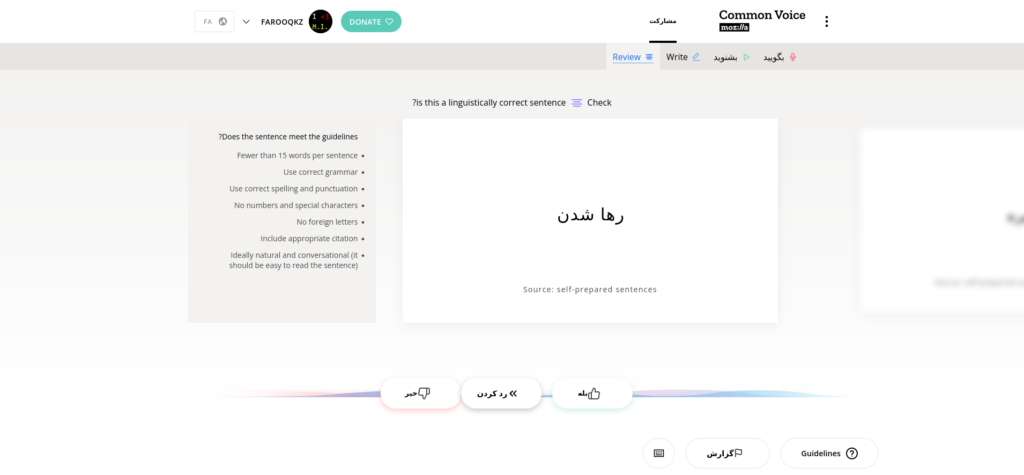
پن: این اواخر سایت آوای مشترک به دلیل بهروزرسانی در بعضی جاها زبان انگلیسی را نمایش میدهد که احتمالا در آینده رفع شود.
دریافت دادههای باز برای کاربردهای محاسباتی یا یادگیری ماشینی
دادههایی که توسط عموم مردم جمعآوری میشود، برای عموم مردم تحت پروانه CC0 که معادل مالکیت عمومی است در دسترس است. برای دریافت دادهها کافیست به صفحهٔ مجموعهٔ دادهها بروید و آخرین نسخه را دریافت کنید.
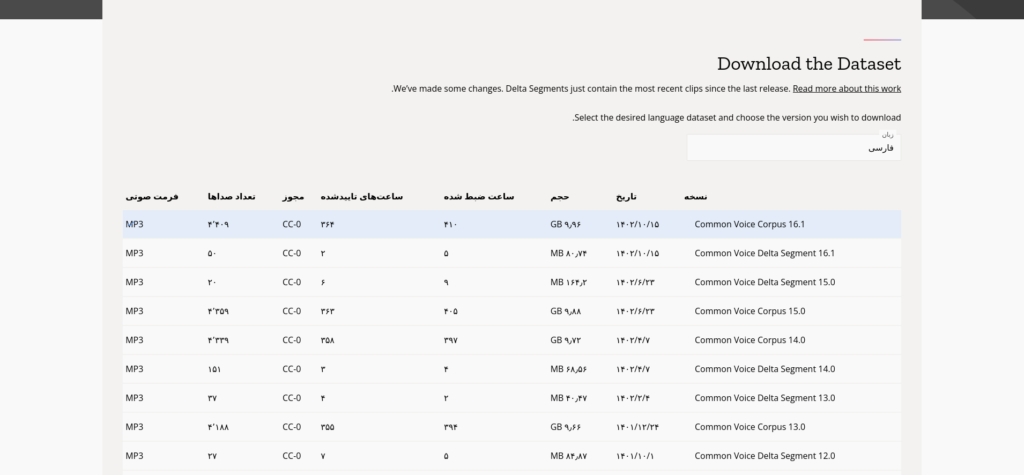
همانطور که در تصویر میبینید، آخرین نسخه دادههای فارسی شامل ۴۴۰۹ قطعه صوتی و به حجم تقریبا ۱۰ گیگابایت است.
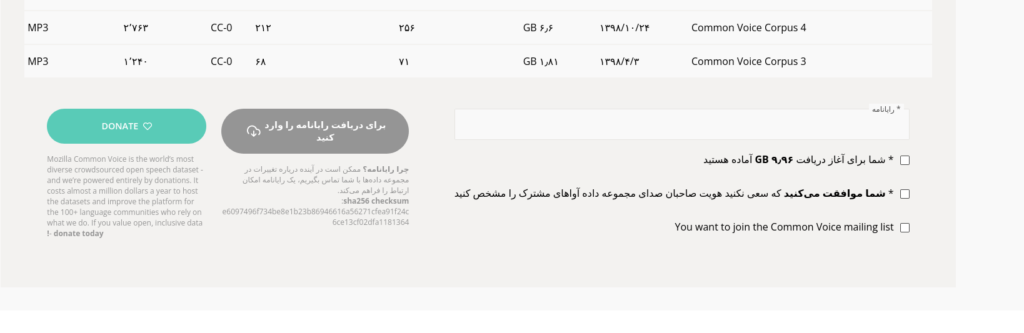
برای دریافت باید آدرس رایانامه(ایمیل) خود را وارد کنید و موافقت کنید که تلاشی مبنی بر پیدا کردن هویت صاحبان قطعههای صوتی نکنید. همانطور که در تصویر میبینید و در اول مطلب بیان کردم، حجم دادههای باز صوتی برای زبان فارسی تنها تقریبا ۲ گیگابایت و ۱۲۴۰ قطعه صوتی بود ولی الان حدود ۱۰GB هست. از همه کسانی که طی چهارسال در گسترش و رشد دادههای باز زبان فارسی مشارکت کردهاند تشکر میکنم.


