یکی از امکانات جالب پایتون دکوریتورها (Decorators) هست؛ که به طور ساده و خلاصه یک تابع هست که در ورودی یک تابع دیگر را گرفته، روی آن اعمالی انجام میدهد و مقداری که باز میگرداند با نام همان تابع ذخیره میشود. اگر با FastAPI کار کرده باشید حتما با این کد آشنایید:
from fastapi import FastAPI,
app = FastAPI()
@app.get("/")
def hello_world():
return {"Hello": "World"}یا برای فلسک (Flask) داریم:
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello_world():
return "<p>Hello, World!</p>"تو این مطلب میخوام بگم جریان این علامت @ چی هست و چه کارایی میتونید باهاش بکنید.
یک دکوریتور چطور کار میکنه
همونطور که قبلا گفتم دکوریتور یک تابع هست که یک پارامتر میگرد و یک مقدار بر میگرداند. خب، با این تعریف که هرچی تابع تک پارامتری داریم دکوریتور میشه! درسته، درواقع چیزی که تفاوت ایجاد میکنه نوع عملکرد علامت @ هست.
نمونه برنامه اول: ایجاد رابط کاربری متنی
فرض کنید برای یک رابط کاربری متنی (CLI) در برنامهتان میخواهید یک دیکشنری (Dictionary) با کلید نام تابع و مقدار تابع کنترل کننده (Handler) داشته باشید. تا بتوانید از آن به این شکل استفاده کنید:
all_commands = {}
...
while True:
line = input("> ")
cmd, *args = line.split()
if cmd not in all_commands:
print("Invalid Command")
continue
all_commands[cmd](*args) # Call the function and send input words (except first) as argumentحالا کد بالا یک خط از کاربر میگیره و با توجه به اولین کلمه در اون خط اگر در کلیدهای دیکشنری بود تابعی که بهش داده بودیم رو روی مابقی کلمات اون خط صدا میزنه مثلا میتونیم توی دیکشنری این رو داشته باشیم:
all_commands["echo"] = printاینطوری اگه یک نفر بنویسه echo hello world برنامه بهش hello world رو نمایش میده. حالا برای توابع بزرگتر باید چیکار کنیم؟ فرض کنید میخواهیم یک دستور (تابع) به نام calc اضافه کنیم تا بتونه محاسبههای ساده رو انجام بده. این تابع به شکل زیر پیادهسازی میشه:
all_commands = {}
def calc(l=None, op=None, r=None):
try:
l, r = int(l), int(r)
except:
print("SyntaxError\n\n usage: calc 2 + 5\nspaces are important")
return
operators = {
"+": lambda: l + r,
"-": lambda: l - r,
"*": lambda: l * r,
"/": lambda: l / r,
"//": lambda: l // r,
}
if op not in operators:
print("operator '%s' is not supported" % op)
return
print(operators[op]())
while True:
line = input("> ")
cmd, *args = line.split()اگه یک دکوریتور مناسب داشتیم میتونستیم مثل کد پایین خیلی خوشگل و شیک این تابع رو هم به دستورات برنامهمون اضافه کنیم:
@command
def calc(l=None, op=None, r=None):
...این همه مقدمه چیدم که اینجا بگم چطور بیاییم و برای این نمونه برنامه دکوریتوری به اسم command بسازیم که هر تابعی که خواستیم به دستورات اضافه کنیم قبلش اون رو بنویسیم و کار رو انجام بده:
all_commands = {}
def command(func: callable) -> callable:
all_commands[func.__name__] = func
return func
@command
def calc(l=None, op=None, r=None):
...به همین سادگی! گفتم که دکوریتور یه تابعه! تابع command که به همراه راهنمای نوع ورودی و خروجیهاش (type hint) نوشتمش، میاد و یک شی صدازدنی (یطورایی همون تابع خودمون!) رو میگیره و همون رو بر میگردونه. تو پایتون مثلا زمانی که این دکوریتور رو واسه calc استفاده میکنیم تابع رو در پارامتر به command میده و چیزی که command بر میگردونه رو به اسم calc ذخیره میکنه. (یعنی اگه command چیزی بر نمیگردوند calc مقدار None میگرفت) توی تابع command اومدیم تابعای رو که توی پارامتر میاد رو توی دیکشنری با اسمش ذخیره کردیم.
کد ما تا اینجای کار این شکلیه:
all_commands = {"echo": print}
def command(func: callable) -> callable:
all_commands[func.__name__] = func
return func
@command
def calc(l=None, op=None, r=None):
try:
l, r = int(l), int(r)
except:
print("SyntaxError\n\n usage: calc 2 + 5\nspaces are important")
return
operators = {
"+": lambda: l + r,
"-": lambda: l - r,
"*": lambda: l * r,
"/": lambda: l / r,
"//": lambda: l // r,
}
if op not in operators:
print("operator '%s' is not supported" % op)
return
print(operators[op]())
while True:
line = input("> ")
cmd, *args = line.split()
if cmd not in all_commands:
print("Invalid Command")
continue
all_commands[cmd](
*args
) # Call the function and send input words (except first) as argument
دکوریتور های پیشرفتهتر!
نمیدونم متوجه فرق دکوریتور ما با اون مثال های اولی که آوردم شدید یا نه، برای دکوریتور هایی که تو مثال های flask و fastapi داشتیم مثلا مینوشتیم @app.get("/") اما تو دکوریتور خودمون فقط داریم مینویسیم @command
جریان اینه که بعضی مواقع تو دکوریتور نیاز داریم که پارامتر های دیگهای هم بگیریم، مثلا فرض کنید تو برنامه بالایی میخوایی بگیم برای اضافه کردن یه دستور به دیکشنریمون میخواییم یه اسم دلخواه و شاید متفاوت با اسم خود تابع اضافه کنیم. (اول این رو میگم و بعد میرسیم به این که چطور تابعی بسازیم که در جاهای مختلف هم اسم خود تابع رو بذاره و هم اسم دلخواه)
مثلا چنین چیزی میخواییم:
@command("for")
def for_function(start=None, end=None):
try:
start, end = int(start), int(end)
except:
print("SyntaxError\n\n usage: for 2 5\nspaces are important")
for i in range(start, end):
print(i)مثلا خواستیم دستور for رو اضافه کنیم ولی چون از کلمه کلیدی های پایتونه نمیتونیم.
برای چنین مواقعی تابعی که برای command تعریف میکنیم وقتی صدا زده میشه یه تابع دیگه بر میگردونه و پایتون تابع هدف رو به تابع برگردونده شده میده. برای همین تابع command اینطوری میشه:
def command(name: str) -> callable:
def decorator(func:callable):
all_commands[name] = func
return func
return decoratorجریان اینه که خود تابع command یه رشته (string) در پارامتر به عنوان اسم دستور میگیره و از اونجا که تو پایتون میشه همینطور تابع تو دل تابع نوشت! یه تابع تعریف میکنه که تابعی که میگیره رو به کلید name تو دیکشنری ذخیره کنه و خود تابع رو مثل قبل برگردونه. تابع command هم وقتی صدا زده میشه تابعی که تو دل خودشه رو بر میگردونه.
دکوریتور ترکیبی
همونطور که قول دادم! اینجا دکوریتوری مینویسم که هر دو حالت بشه ازش استفاده کرد. البته روشهای مختلفی هست ولی این یک مدلشه:
def command(f: str) -> callable:
def decorator(func: callable):
all_commands[name] = func
return func
if isinstance(f, str):
name = f # `f` is a string so it is the name
return decorator
else:
# `f` is not a string so may be it's a callable
name = f.__name__
# this code may raise AttributeError,
# but this is a simple example, isn't?!
return decorator(f)تو این کد چک میکنیم ببینیم پارامتری که به command اومده از چه جنسیه، اگه رشته بود پس اسم دستور هست و اگر نه خود تابع دستور هست. در هر دو صورت اسم دستور با متغیر name تعیین میشه، وقتی رشته بود name برابر میشه با رشته داده شده و خود تابع داخلیه فرستاده میشه؛ چون توی کد این تابع به شکل @command("example") صدا زده شده، پس باید یه تابع تحویل پایتون بده که پایتون تابع هدف رو به اون بفرسته. در غیر این صورت احتمالا پارامتره یه تابعه (چون این دکوریتور رو برای خودمون مینویسیم زیاد پیچیدهش نکردم که همه چیز رو چک کنه!) پس به صورت @command صدا زده شده و یه تابع بهش داده شده، مثل قبل اسم تابع رو تو name ذخیره کنه و خودش تابع توی دلش رو روی این تابعی که گرفته صدا بزنه
نمونه برنامه دوم: استفاده از @property در پایتون
یادش بخیر، اون زمان ها که من C# کد میزدم یه چیز باحالی داشت به نام property بعدا که اومدم سراغ پایتون دنبالش گشتم و دیدم پایتون هم یه چیزی مشابهاش داره ولی از دکوریتور براش استفاده میکنه. جریان چیه حالا!
این property تو کلاسها هست و یکجور فیلده که موقع گرفتن مقدار یا ذخیره مقدار توش در واقع یه تابع صدا زده میشه. قبلا در مورد dataclass گفتم، اینجا برای این مثال ازش استفاده میکنم تا مجبور نباشم تابع __init__ رو بنویسم، دوست داشتید اون مطلبم رو هم بخونید.
from dataclasses import dataclass
from datetime import date, datetime
@dataclass
class Person:
name: str
birth_date: date
@property
def age(self):
return (date.today() - self.birth_date).days // 365حالا اگه یه نمونه از این کلاس بسازیم میتونیم فیلد area رو مثل بقیه فیلد ها بگیریم ولی هر بار این فیلد با توجه به دو مقدار ارتفاع و عرض محاسبه میشه:
me = Person("Behnam", date(2000, 9, 29))
print(me.age)حالا اگه بخواییم این property(خصوصیت) مقدار هم بگیره میتونیم براش یه setter مشخص کنیم:
from dataclasses import dataclass
from datetime import date, timedelta
@dataclass
class Person:
name: str
birth_date: date
@property
def age(self):
return (date.today() - self.birth_date).days // 365
@age.setter
def age(self):
self.birth_date = date.today() + timedelta(value*365)
یکی از امکانات جالب در پایتون ۳.۷ به بعد اضافه شدن dataclass هست. امروز و در این پست نگاهی به این کتابخوانه میکنیم و از ماژول مورد علاقه خودم برای مدلسازی pydantic هم خواهم گفت.
کلاس داده (Dataclass)
در بسیاری از پروژه ها قالب های داده داریم مثلا شخصی که در سیستم ثبت میشود دارای فیلد های داده مانند نام، نشانی، سن، آدرس ایمیل و … است (جداً برای فیلد هیچ معادل فارسی درستی پیدا نکردم!). یکی از روش های نگهداری و استفاده از این داده ها که ساختار و فیلد های مشخصی دارند استفاده از dataclass است.
در واقع dataclass یک decorator از کتابخانهی dataclasses است. کلاس داده تفاوت یا محدودیتی نسبت به یک کلاس معمولی پایتون ندارد اما میتواند کار را سادهتر کند چون که این دکوریتور خودش توابع __init__() و __repr__() را ایجاد میکند.
from dataclasses import dataclass, field
@dataclass
class Person:
name:str
lastname:str
age:int = 0
address:str = ""
children: list["person"] = field(default_factory=list)کد بالا یک مدل داده برای یک فرد را میسازد. دکوریتور dataclass همراه با توابع دیگر یک تابع init مانند زیر ایجاد میکند:
def __init__(self, name:str, lastname:str, age:int = 0, address="", children=[]):
self.name = name
self.lastname = lastname
self.age = age
...دقت کنید که هنگام ایجاد کلاس داده استفاده از typehint ضروری است. typehint (راهنمای نوع؟!) یک شیوه نوشتار در پایتون برای اشاره به نوع داده یک متغیر است. مثلا:
age:intفاروق در همین مورد این مطلب رو نوشته:
استفاده از تابع field در کلاس های داده
همونطور که در مثال بالا آمده برخی فیلدها میتوانند داده پیشفرض داشته باشند (در مثال age, address و children) اما باید دقت کنید که برای داده هایی که اسطلاحاً mutable هستند مانند list, dict ,… برای این که مشکلی پیش نیاد باید از تابع field استفاده کنید تا یک تابع مثلا list() را هنگام ایجاد یک نمونه صدا بزند و خروجی را در فیلد ذخیره کند (در غیر این صورت یک لیست مشترک بین همه نمونه ها خواهید داشت که میتواند برایتان ایجاد مشکل کند).
from datetime import datetime
@dataclass
class book:
name:str
author:str
was_added_at:datetime = field(default_factory=datetime.now)
owners:list[Person] = field(default_factory=list)در کد بالا برای فیلد «تاریخ اضافه شدن» هنگام ایجاد یک نمونه تابع now() صدا زده میشود که تاریخ فعلی را باز میگرداند (البته اگه در ورودی ها تاریخ دیگری داده شد جایگزین میشود)
ماژول pydantic
اگر امکانات بیشتری نیاز داشتید حتما نگاهی به ماژول pydantic بیاندازید. این ماژول کامل با هدف مدلسازی داده و اعتبارسنجی داده هاست. این ماژول امکانات زیادی داره مثل خواندن و خروجی به فرمت های مختلف مثل json، تولید schema و …
جدا از این که با linter ها و ویرایشگر های کد به خوبی کار میکند در بسیاری از ماژول های دیگر مانند FastAPI, Beanie و … استفاده شده.
from datetime import datetime
from pydantic import BaseModel, PositiveInt
class User(BaseModel):
id: int
name: str = 'John Doe'
signup_ts: datetime | None
tastes: dict[str, PositiveInt]این ماژول علاوه بر این که همانند یک dataclass به شما امکان دسترسی به فیلد ها مختلف با نوشتار نقطهای میدهد (dot notation) و ویرایشگر کد شما نیز به خوبی شما را راهنمایی میکند، صحت داده ها را میسنجد، مثلا نمیتوانید برای فیلد id که از جنس عدد است یه متن وارد کنید. (البته pydantic دوست داشتنی، رشته "12" را به عدد تبدیل میکنه و گیر نمیده ولی اجازه نمیده که مثلا "foobar" ذخیره بشه)
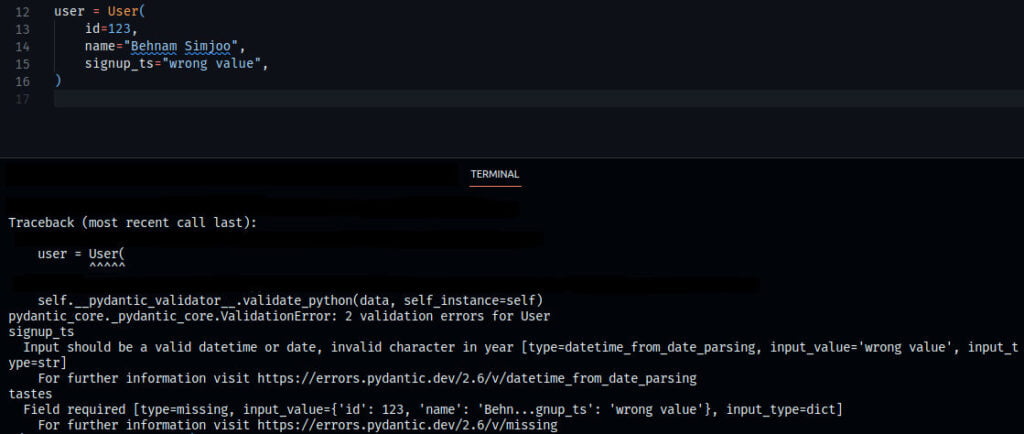
مقایسه pydantic با dataclass
ماژول pydantic تمام نیاز هایی که هنگام استفاده از dataclass دارید را به خوبی پاسخگو هست و به شما بسیاری امکانات بهتر و مفیدتر می دهد، برای مثال تبدیل یک نمونه به JSON و بلعکس به همراه اعتبارسنجی داده ها به سادگی انجام میشود و نوع داده های مختلفی مثل آدرس ایمیل، عدد مثبت و حتی نوع داده سفارشی شما را پشتیبانی میکند. کلی امکانات دیگر نیز هستند که همهی آن ها را در مستندات کامل این ماژول در سایتشون میتونید بخونید.
 و ماژول pydantic")
سلام! جعفر هستم و این اولین نوشتهام توی وبلاگ کرم های کامپیوتره 🙂
حالا قراره درباره چی حرف بزنم؟ یک چند وقتی درگیر این بودم که لیبرهترنسلیت که یک مترجم آزاده(این) رو برای زبان فارسی بهبود بدم. یعنی کاری کنم که ترجمه بهتری برای زبان فارسی داشته باشه.
قبلش بگم که لیبره ترنسلیت چیه؟
لیبره ترنسلیت یک نرمافزار ترجمه ماشینی آزاده که بر پایه کتابخانههای آرگوز ترنسلیت(argos-translate) توسعه داده شده که با یک رابط تحت وب به صورت سرویس ترجمه ماشینی نامتمرکز در دسترسه. مثلا نمونهای که توسط توسعهدهندگانش مدیریت میشه اینه:
درباره نحوه کارکرد و زبانهایی که پشتیبانی میکنه میتونید توی صفحه گیتهابشون بخونید.
حالا من میخواستم چیکار کنم؟
با توجه به اینکه لیبره ترنسلیت یک مدل هوشمصنوعی ترجمه ماشینی(البته نه دقیقا یک مدل) هستش ساختار کلیاش اینه که با یک حجم بالایی داده ترجمه به دو زبان(مبدا مثلا فارسی و مقصد مثلا انگلیسی که دوتا مدل آموزش میبینه یکی مبدا به مقصد و یکی برعکسش) نیاز داره، که اینجا هدفمون فارسی بود. اولین کار این بود که ببینیم مشکل این کیفیت پایین ترجمه چیه. رفتم یک دوری زدم و به داده هایی که مدل فارسی باهاش آموزش دیده رسیدم. حدود پنج میلیون خط ترجمه که کیفیت جالبی هم نداشت.
راهکار این بود که داده های بهتری جمع کنیم و مدل جدید آموزش بدیم. این کار رو کردیم و دوستانی هم کمک بسیاری کردند در این مسیر و حدود ۲ میلیون خط ترجمه جمع شد(عموما سر هم کردن دیتاست های آزاد دیگه). یک دوست عزیز دیگهای لطف کردند سخت افزارشون رو برای آموزش مدل در اختیار من گذاشتن(برای آموزش اینجور مدلها به سخت افزار قوی از جمله GPU قوی نیازه که من ندارم :) و مدل رو با حدود پنج ساعت پردازش آموزش دادیم، اما خروجی از مدل لیبره ترنسلیت هم بدتر بود!
با عیبیابی به این نتیجه رسیدیم که هم کیفیت این دادهها کافی نیست و هم حجمشون. مشکل دیگه این بود که بخش قابل توجهی از دادهها ترجمه واژهنامهوار (و نه جمله در برابر جمله) بود که کار رو خراب میکرد.
یک مدتی گذشت در همین موضوع من یک برنامه ای چیدم برای حلش و یک ارائهای در دورهمیهای کرمهای کامپیوتر دادم. با این موضوع که که چه کنیم که مشکل رو حل کنیم. دوستان لطف کردن کمک کردن و همچنین حمایت بیشتر :))
خواستیم شروع کنیم من یک مقدار اسکریپت برای خودکار کردن استخراج داده، از اینترنت و تبدیلشون به ترجمه با گوگل ترنسلیت، نوشتم و یکم داده جمع شد، بعد از چند روز که داشتم توی اینترنت چرخ میزدم به این لینک رسیدم:
https://opus.nlpl.eu/NLLB/en&fa/v1/NLLB
همینجا بود که فهمیدیم این همه کار به قولی الکی بوده :/ یعنی چی؟ یعنی ما برنامه داشتیم با کلی پردازش و بازبینی انسانی ۵ میلیون خط ترجمه خوب جمع کنیم اما اینجا حجم بسیار بزرگی یعنی ۲۵ میلیون خط ترجمه انگلیسی به فارسی به حجم ۴۷ گیگابایت خوابیده بود!
حالا چرا پیگیر آموزش مدل نشدم؟
اول اینکه من سخت افزار لازم رو برای آموزش نداشتم، و اینکه اگه کسی مثل دفعه قبل زحمت آموزش رو میکشید مثلا با اون سختافزار قبل (یعنی گرافیک با ۱۲ گیگابایت حافظه ویدئویی) و اگه زمان آموزش رو خطی فرض کنیم ۶۲.۵ ساعت نیاز بود که گرافیک جون بکنه که با این حجم داده مدل رو آموزش بده! و این از توان من خارجه.
و باید چیکار کرد؟
این کار متاسفانه خارج از توان منه. اما اگر کسی بخواد این کار رو انجام بده نیاز داره به کارت گرافیک قوی و زمان برای آموزش یا اگه اینها رو نداره میشه دو سه روزی یک سرور GPU دار اجاره کنه و این کار رو انجام بده، البته کمک دیگهای برای این کار نیاز باشه من میتونم همین چند خط تجربهای که سر این موضوع کسب کردم در اختیارش بذارم 🙂
سلام! به مسئلهای برخوردم که نیاز داشت یه آرایه با طول نامعلوم رو از کاربر بگیریم. اینطوری که کاربر شروع میکنه به وارد کردن ورودیها تا زمانی که کلمه end رو بزنه و تموم کنه. مسئله سادهای هست و در کل زیاد چیز شاخی نیست!!
چالشش اینه که ما تعداد اعضا رو نمیدونیم و طول آرایه هم ثابته کنه، پس در حالت عادی مجبوریم ورودیها رو بریزیم تو یه لیست تا آخرش که کار کاربر تموم شد همه رو مثلا منتقل کنیم به یه آرایه با طول لیسته، یعنی داریم دو بار هر عضو رو بررسی میکنیم که هزینه زمانی اینجا میشه 2n(معادل O(n)) از طرفی توی زبانی مثل C که اصلا لیست نیست و باید مثلا از SLL(به انگلیسی: Singly Linked List و به فارسی: فهرست پیوندی یکطرفه) استفاده کرد.
#include <stdio.h>
#include <stdlib.h>
double* rec(int i) {
char input[100]; // Adjust the input string size as needed
fgets(input, sizeof(input), stdin);
if (strcmp(input, "end\n") == 0) {
double* result = (double*)malloc(i * sizeof(double));
return result;
}
double* arr = rec(i + 1);
sscanf(input, "%lf", &arr[i]);
return arr;
}
int main() {
double* result = rec(0);
// Printing the result
for (int i = 0; result[i] != 0.0; ++i) {
printf("%lf ", result[i]);
}
free(result); // Free the allocated memory
return 0;
}مشابه این کد در پایتون به این شکل نوشته میشود(برای آرایه از numpy استفاده شده).
from numpy import np
def rec(i=0):
inp = input()
if inp == "end":
return np.zeros(i)
arr = rec(i + 1)
arr[i] = int(inp)
return arrدر واقع این شیوه به شکلی هوشمندانه از پشته(به انگلیسی: stack) خود سیستم برای ذخیره موقتی اعضا و شمارش آن ها استفاده میکنه. اما باید دقت کنید که این روش نامحدود هم نیست چون به اندازه پشته محدود میشه.

روبوکد یک بازی برنامهنویسی است که در آن با زبان جاوا، اقدام به برنامهنویسی کردن روباتهای کوچکی میکنید که با بقیهٔ روباتها باید بجنگند. مبارزه میتواند به صورت تکبهتک با یک روبات دیگر یا به صورت گروهی با مثلاً ۹ روبات دیگر باشد. هرچند که باید روباتهای خود را به زبان جاوا بنویسید، اما دانش عمیقی از این زبان مورد نیاز نیست و در صورتی برنامهنویس یکی از زبانها از همین خانواده باشید، میتوانید بهراحتی یک روبات بسازید.
توضیح خاصی ندارم…
let father: &Individual = loop {
i = rng.gen_range(0..pop_size);
if rng.gen_bool(self.population[i].ft() / total_ft) as f64){
break &self.population[i];
}
}
در این مطلب میگیم که چطور میشه در پایتون یک پروسه دیگر را اجرا کرد و خروجی استاندارد و ورودی استاندارد رو بگیریم و ازش استفاده بکنیم. خروجی و ورودی استاندارد همون چیزایی هستن که تو محیط متنی چاپ میشن یا کاربر توی ورودی برنامه وارد میکنه. در واقع توی این مطلب یاد میگیرید که چطور میتونید در پایتون با برنامه های کنسولی دیگه تعامل کنید.
پایپ (pipe) چیست؟
به طور پیشفرض سیستمعامل ورودیها رو از موس و کیبورد میگیره و خروجیها رو روی صفحهنمایش مینویسه. اما در بعضی مواقع نیاز هست که یک برنامه از خروجیهای یک برنامه (یا دستور) دیگه استفاده کنه یا به ورودی استاندارد یک برنامه داده ارسال کنه. در چنین شرایطی pipe استفاده میشه. pipe یک فضای موقتی در حافظه برای جابهجایی اطلاعات بین دو برنامه هست که البته یک طرفه هم هست؛ یعنی مثلا برای گرفتن خروجی باید از یک pipe و برای نوشتن ورودی هم از یک pipe دیگر باید استفاده کرد.
زبانها معمولاً یا تعیین نوع پویا دارند؛ مانند کامن لیسپ، پایتون، جاوا اسکریپت یا دارای تعیین نوع ایستا هستند؛ مانند سی و سیپلاسپلاس، راست و دوباره کامن لیسپ (معمولاً پیادهسازیهای مدرن کامن لیسپ، مانند SBCL، اجازه میدهند بنا به خواست برنامهنویس، قسمتی از کد، دارای تعیین نوع ایستا و قسمتی دارای تعیین نوع پویا باشد).
در پایتون، تعیین نوع متغیرها، مقدار یا مقادیر بازگشتی توابع و متدها و آرگومانهای توابع اجباری نیست. اما میتوانیم با تعیین نوع و استفاده از یک نرمافزار Linter به کاهش خطاهای خود پیش از اجرا کمک کنیم.
def f(x: int) - > int:
return x * 2 + 1با این که تعیین نوع آرگومان یا ورودی تابع f که x باشد و مقدار بازگشت آن یعنی x*2 + 1 در اجرا تأثیری ندارد، اما زمانی که بخواهم مقدار بازگشت تابع f را با یک رشته نویسه (کاراکتر) جمع کنم به من اخطار داده میشود:
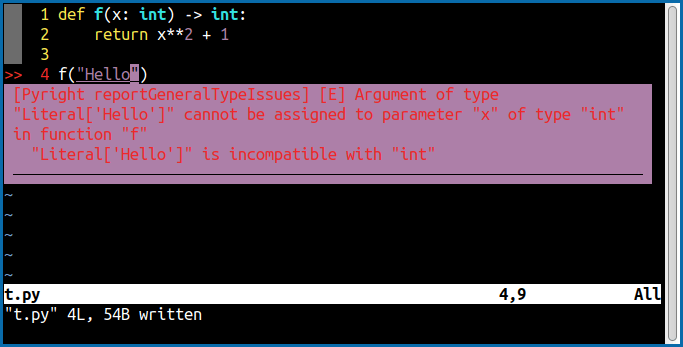
بدیهی است که اجرای این برنامه به وسیلهٔ پایتون نیز باعث خطا میشود. در مقابل زمانی که نوع ورودی و خروجی تابع را مشخص نمیکنم اخطاری داده نمیشود:
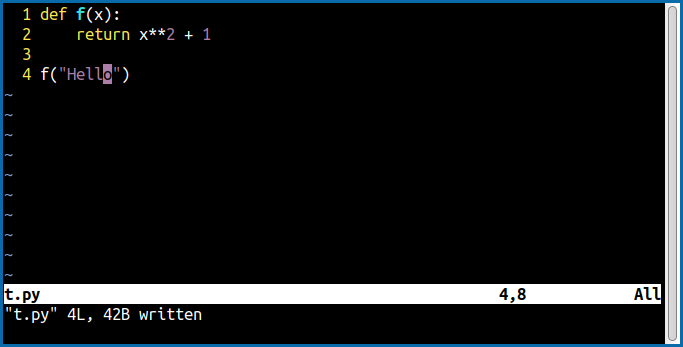
در ادامه با تعیین نوع ورودیها و خروجی توابع و متدها و ویژگیهای یک کلاس آشنا میشویم.
زمانی که از یک برنامهنویس پایتونی بخواهید یک تابع ساده بنویسد تا ارقام یک عدد را جمع کند و برگرداند، احتمالاً ابتدا عدد را به یک رشته تبدیل میکند و سپس رشته را به لیست (فهرست) و نهایتاً تکتک اعضای لیست را که ارقام عدد به صورت رشتههای تکنویسهای هستند به عدد تبدیل میکند و سپس آنها را با هم جمع میکند. ولی الزاماً اولین روشی که برای حل مسئله به ذهنمان میرسد، بهترین روش نیست. در این مطلب دو الگوریتم برای جمع ارقام یک عدد صحیح به صورت بازگشتی و تکرارشونده به همراه کد های پایتون آن ها ارائه میدهم.
مسئلهٔ ۸ وزیر یک تمرین معروف در علوم کامپیوتر و ریاضیات میباشد. این مسئله در مورد یک صفحهٔ شطرنج رایج و مهرهٔ وزیر در این بازی فکری میباشد. در ریاضیات ثابت میشود که میتوان ۸ وزیر را در یک صفحهٔ شطرنج چنان قرار داد که هیچکدام از وزیرها، دیگری را تهدید نکنند. با تعمیم این مسئله در ریاضیات، ثابت میشود که در یک صفحهٔ شطرنج به ضلع n، میتوان تعداد n وزیر قرار داد؛ چنانچه هیچکدام دیگری را تهدید نکنند. در علوم کامپیوتر میتوان با روشهای مختلفی این مسئله را حل کرد و به یک چینش از مهرههای وزیر رسید که هیچکدام دیگری را تهدید نکنند. یکی از این روشها «الگوریتم ژنتیک» است.
طی دهههای گذشته بحثهای زیادی راجع به اینکه مشخصات زبانهای برنامهنویسی، به عنوان مثال تعیین نوعشان و مثلا ایستا(static) یا پویا(dynamic) بودن چه تاثیری روی روند توسعه نرمافزارها دارد. یک مقاله علمی(paper) با مطالعه ۶۰۰ پروژه در گیتهاب شامل تقریبا ۷۰ میلیون خط کد و ۳ میلیون کامیت به نتایجی در این مورد رسیدهاست.
اینکه برای یادگیری برنامهنویسی دانستن زبان انگلیسی لازم هست یا نه، پرسش بسیاری از کسانی هست که میخواهند برنامهنویسی را شروع به یادگیری کنند. در این پست بنده با توجه به تجربهی خودم سعی میکنم به این پرسش جواب دهم. اگر نمیخواهید کل مطلب را بخوانید، جواب کوتاه این پرسش در یک جمله این است که «بله، برای یادگیری برنامهنویسی باید حتما انگلیسی هم یاد بگیرید»